Production rental marketplace with AI-powered semantic search, map-based discovery, payments, and 8-language localization.
Two-sided rental marketplace shipped as a Turborepo monorepo — a Next.js 15 web app and a standalone search-indexer microservice that isolates reindexing from user-facing API latency.
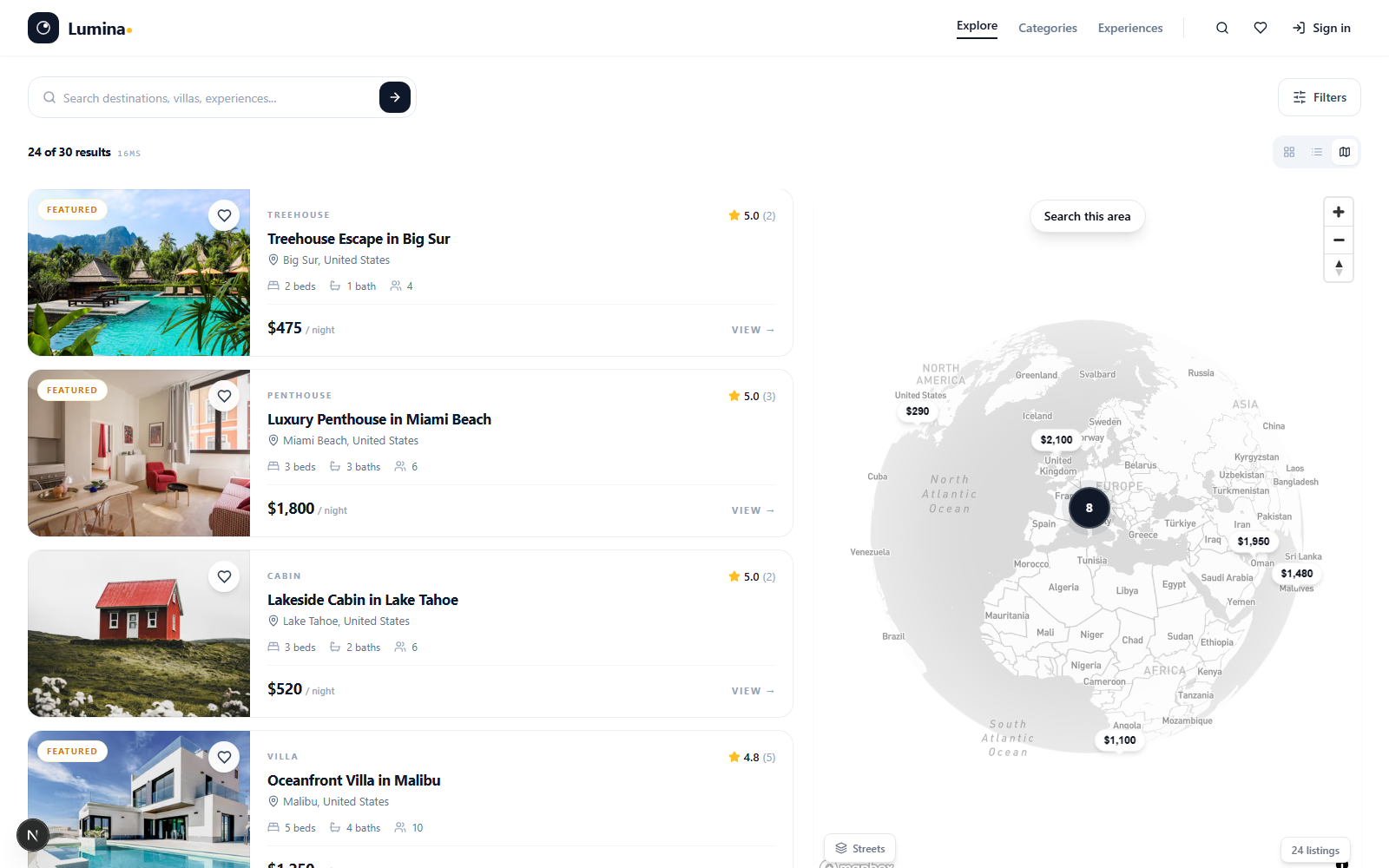
- Three-tier search: pgvector HNSW for semantic matching, Meilisearch for typo-tolerant facets and geo, PostgreSQL full-text as graceful fallback.
- Mapbox GL with Supercluster clustering, Stripe Connect for marketplace payments and host payouts, OAuth 2.0 with Google and Apple.
- AI-streamed listing descriptions via the Anthropic Claude API, OpenTelemetry distributed tracing to Jaeger, PWA with offline fallback.
- Multi-stage Docker and Kubernetes manifests with cert-manager TLS; 58 unit/integration tests + Playwright E2E in GitHub Actions CI.
Lumina is a Turborepo monorepo with two services. The Next.js 15 web app handles all user-facing surfaces — App Router for pages, route handlers for the API, edge middleware for auth/geo/bot detection, ISR with tag-based cache revalidation for listing pages. A separate `search-indexer` Node service consumes BullMQ jobs to index listings into Meilisearch and generate pgvector embeddings via OpenAI. Splitting it out matters: bulk reindex storms can't degrade user-facing API latency, and the indexer scales independently. 25 Drizzle tables, 80 REST endpoints, 8 i18n locales via next-intl.
Modular monolith, not microservices
Single team, single deployment pipeline. Splitting auth / listings / bookings / favorites into microservices adds network latency, distributed-transaction complexity, and operational overhead with zero benefit at this scale. Module boundaries enforced via shared types — not network calls.
Three-tier search instead of one engine
Semantic queries ("cozy cabin near the ocean") need vector similarity → pgvector HNSW. Keyword + facets + geo need a real search engine → Meilisearch. Both can fail; Postgres full-text is a graceful fallback. The route handler picks the tier per query type.
Drizzle over Prisma
Better runtime perf, SQL-like DX, smaller ecosystem. The trade was worth it: queries read like SQL, the type inference is exhaustive, and the migration story is simpler. Prisma's tooling is nicer; Drizzle's queries are nicer.
Denormalized rating + reviewCount on listings
Listing pages are read-heavy. JOIN + GROUP BY on every page load to compute the rating is expensive. Storing rating + reviewCount on the listings row, recomputed on every review write, with `revalidateTag('listing:{slug}')` to bust cache, gives near-real-time freshness with zero per-request DB hits.
OpenTelemetry traces propagating through BullMQ jobs
Auto-instrumented HTTP, Postgres, and Redis. Manual spans on bookings, search, auth, email. The W3C `traceparent` header propagates from API → BullMQ job data → indexer service, so a single trace in Jaeger spans the whole pipeline.